After my post last week, which argued that the deceiving Kerry “leads” in four battleground states fell well short of statistical significance required for a projection, especially given the 99.5% confidence level required by NEP, I got this comment from an alert reader via email:
If we really adhere to confidence intervals of the sort you (or NEP propose) of somewhere between 5 and 8%, exit polls are COMPLETELY USELESS. Eighteen states would not have been able to have been called (there margins were within the confidence intervals), and these 18 states were the only interesting states. An idiot who looked at the column of safe states for each candidate [and then] flipped a coin for the battleground states would do as well as exit pollsters
Actually, he has a point. The dirty little secret is that the exit polls alone are almost never used to project winners in seriously contested states, or (as the reader put it) in states where the winner was not already perfectly obvious 24 hours before the election.
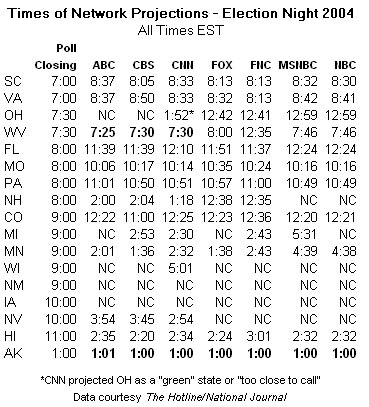
Don’t take my word for it. Consider the states the networks called at poll closing time. My friends at National Journal’s Hotline provided a listing they compiled of when the networks called each of the “top purple states.” Of these, only Alaska and West Virginia were called at poll closing time on the basis of exit polls alone (WV was called at that time by only three networks), and few still considered those states truly competitive by Election Day. All of the true “battleground” states were called later in the evening on the basis of actual results.
Or you could have asked Warren Mitofsky a few years ago. In January 2001, he made the following recommendation to CNN for future Election Night projections:
In order to project the winner in an election based solely upon exit poll data, the standard for an estimated vote margin will be increased from 2.6 standard errors to four standard errors – i.e. a Critical Value of 4.0 instead of 2.6 will be necessary for a “Call Status” based entirely on exit poll data [page 51 of the pdf].
A “critical value” is a number that specifies the level of confidence in the formulas that calculate the margin of error. In this case, a critical value of 4.0 is the equivalent of 99.997% confidence level and much wider margins of error than those used this year, which were based on a 99.5% confidence level. In plain English, Mitofsky’s recommendation (which the networks apparently did not adopt) was to use exit polls to project winners only when they show a candidate cruising to a huge landslide victory.
So why do the networks shell out millions of dollars for exit polls? First, they do care about making projections as quickly as possible in the non-competitive states. While it is true that your or I could probably have “called” states like Indiana, Oklahoma or Massachusetts the day before the election with complete accuracy, news organizations are supposed to report only what they “know,” not what they think they know. The exit polls in all the obvious states, with their huge, easily statistically significant margins provide hard confirmation of what everyone expects and thus provide a factual basis for the early projections.
Second, they use the exit polls to fill airtime on election night with analysis about why the candidates won and lost. Or as the CNN post-election report put it less cynically in 2001: “Exit polling provides valuable information about the electorate by permitting analysis of such things as how segments of the electorate voted and what issues helped determine their vote.” Four years ago, that same report argued against using exit polls to project winners, but endorsed the use of exit polls for analytical purposes. They concluded (p. 8 of the pdf):
Total elimination of exit polling would be a loss, but its reliability is in question. A non-partisan study commission, perhaps drawn from the academic and think-tank communities, is needed to provide a comprehensive overview and a set of recommendations about exit polling and the linked broader problems of polling generally.
Perhaps it is time to reconsider that recommendation.
This discussion misses two key Points!
a) Discussing how large a confidence interval you require before projecting a result is a silly discussion to have if your poll has a SYSEMATIC bias. Heck if they had polled samples 100 times as big they probably could have called almost all the states, yet their calls would not be much more accurate.
b) Can anyone give me one good reason, why it is impossible to do an exit poll without bias? Why are people not even discussing the changes that need to be made to do these polls without bias?
Hi Brian,
Would you agree that the German Exit polling model, which admittedly is probably very expensive and invovles governmental census work during the election, provides a model for a good exit poll?
Of course, I don’t think it likely the US would actually allow elections to be “audited” systematically, and an accurate Exit Poll would amount to an audit of the election. I don’t think either party has the courage to open up that can of worms yet.
Can we the people muster the courage to look our fears in the eye, face the bullying and propaganda of the vested interest, and demand a reformed election system? I hope so, but we also need leaders.
Ok, this post should go on DailyKos, not here. Sorry.
Mark,
Don’t exit polls also provide uniquely valuable voter profile data?
Also, assuming the exit poll vote counts are systematically biased by non-response, et al, is the voter profile data then equally biased? Reweighting to match election results presumably increases the accuracy of the voter profiles, but is that still the case past a certain threshold of discrepancy between the exit polls and election results?
It seems that with a large enough discrepancy both the exit poll and election results might be called into question and reweighting becomes much less effective.
I ask because you have not addressed much how the exit poll discrepancies may affect the validity of the reweighting process and its results.
Thank you.
The discrepancy is explained. Apparently the standard 2 standard deviations used in scientific inquiry was not used. Rather on this Website the ridiculously high 4 standard deviations or a signifance level of 3 x 10-5
is the Motovsky standard. This is a diference of three orders of magnitude in significance. I can tell you now that if this level was adopted in normal scientific discourse hardly a paper which was not pure theory would ever be published.