Tonight I want to take up some additional questions readers have asked about the new exit poll data, specifically those about the regional composition of the national sample. For those who would rather not slog though a long post, I’ll cut to the chase: Though there is much confusion about the mechanics of a very complex set of surveys, I see nothing here to substantiate the wilder allegations of hoax and fraud. If you’re interested in the details, read on.
A review: Scoop, a New Zealand web site, recently put a set of PDF files online that were apparently created on Election Day by Edison/Mitofsky, the company the conducted the national exit poll, and distributed to their newspaper subscribers. The files are cross-tabular tables (“crosstabs” for short) for two questions (the vote for President and for U.S. House of Representatives), released at three different times (3:59 pm or 7:33 pm on Election Day and 1:35 pm the following day), tabulated separately for the national sample and four regions (East, South, Midwest and West) with each table run in two different formats (one with vertical percentages, one with horizontal percentages).
Most of the questions that have come up concern some odd inconsistencies regarding number of interviews conducted nationally and in the four national regions. The table that follows shows the unweighted sample sizes (“n sizes”) for the presidential and Congressional vote crosstabs:
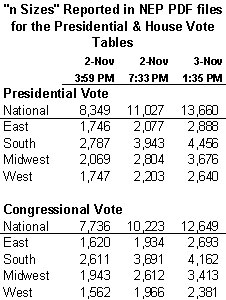
One important note: All references to “unweighted interviews” in this post refer to the n-sizes reported in the PDF files. As we learned Monday, this number is inflated because 500 interivews conducted nationally by telephone among absentee and early voters were replicated four times in the unweighted data. This programming oddity did not affect the tabulated results for the presidential and congressional vote questions, because the telephone interviews were weighted back to their appropriate value (see Monday’s post for more explanation).
Here are the issues that puzzled MP’s readers:
1) Why are the unweighted counts on the cross-tabulations of the presidential vote question always larger than on the tabulations for vote for House of Representatives?
The table below shows the difference between the unweighted sample sizes for questions on the Presidential and U.S. House votes, in terms of raw numbers and percentages.
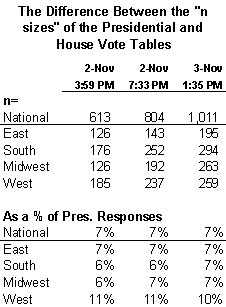
In every sampling, the unweighted number for the presidential vote was greater than for the congressional vote. For example, the n-size of the national presidential vote crosstab at 1:35 pm on 11/3 (n=13,660) is 1,011 “interviews” higher than on the congressional vote crosstab (n=10,223). As a percentage of the unweighted presidential question n-sizes, the differences are consistently between 6% and 7% (slightly larger in the West). Why?
The answer seems simple: Many who turn out on Election Day cast a vote for president but skip the lesser offices. In the 2000 election, according to America Votes, there were 105.4 million votes cast for President and 97.2 million for the U.S. House. The difference was 7.8% of the presidential vote – roughly the same percentage as the difference on the exit polls.
2) Why are there so many interviews in the Midwest and South? Is that plausible?
The first and most pointed commentary on this issue came from Steve Soto of TheLeftCoaster. Among other things, he argued:
[Mitofsky] had to pull 60% of his final exit poll sample from the South and the Midwest in order to make his final national exit poll reflect the tallied results. I ask you: how plausible is all of this?
Soto used the unweighted n-sizes above to arrive at the 60% figure. The weighting done by NEP on Election Day is primarily regional (to match turnout, as discussed on this site many times, especially here). We also now know that the unweighted tallies quadruple-counted the telephone interviews of early voters. Thus, the raw, unweighted data may be way off before the regional weights are applied.
However, even if we ignore all that, the size of the unweighted South and Midwest samples are not as far from reality as Soto may have assumed. I did my own tabulations on the unofficial returns widely available in mid-November using the regional definitions from the VNS exit polls four years ago: Those show 25% of all votes cast nationally coming from the Midwest region and 32% in the South for a total of 57%. So the even the unweighted interviews look a little high in the South and Midwest regions, but not that much.
Of course, the unweighted n-sizes are largely irrelevant to questions about the exit poll results. The real question is what the weighted distributions looked like. They should have been spot-on, because the exit poll data are supposed to be weighted to represent the best available estimate at any given time of the ultimate regional distribution of voters. You need not take my word on this. Just open any of the crosstabs for the Presidential vote (3:59 or 7:33 pm on 11/2 or 1:35 pm on 11/3) or the Congressional vote (3:59, 7:33 or 1:35). Scroll down to the bottom and you will find tabulations for the four regions. The left column has the percentage of weighted interviews for each region. I have reproduced the table of all of these values below.
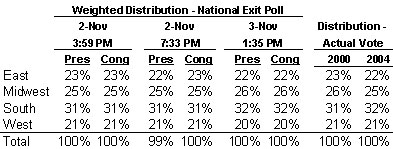
The point of this table is simple. The numbers show only a slight variation over the course of the day (that reflects the ever improving estimates of turnout) and ultimately match up almost perfectly with the ultimate regional distribution of votes cast. The unweighted n-sizes are irrelevant. Whatever the failings of the national exit poll, the national data were weighted appropriately throughout the day to match the true distribution of likely voters.
3) How could 811 new unweighted interviews appear in the East region between 7:33 p.m. on Election Night and 1:35 p.m. the next day? Why were comparatively few new interviews added after 7:30 EST in the West?
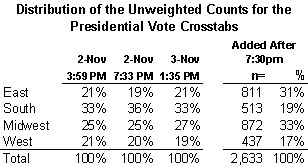
The table below shows the regional composition of the unweighted interviews for the three releases, as well as those that were added to the NEP data after 7:33 p.m. on Election Night: Note that 31% of the interviews added after 7:30 p.m were in the East and only 17% in the West. How can that be?
What follows is an educated guess, but I believe the answer is evident in both the poll closing times and the distribution of early and absentee voters interviewed by telephone.
Let’s start with poll closing times. As explained on this site previously, the NEP training materials instruct interviewers to suspend interviewing and call in their last batch of results approximately an hour before closing time. Some time is obviously necessary to key in these data and do additional data runs so that complete exit poll data is available to network decision makers in each state shortly before the polls close. Presumably, the 7:33 p.m. cross tabs represent complete exit poll data for States that closed at 7:30 p.m. EST or prior, but may have been missing many of the final reports for states that closed at 8:00 p.m.
The official NEP site provides poll-closing information for all 50 states. I had not noticed this before, but only two of the nine states whose polls close at 7:30 or earlier (Vermont and West Virginia) fall into NEP’s East region. Two are classified as Midwest (Ohio and Indiana), five as South (Georgia, Kentucky, North Carolina, South Carolina, Virginia). So it follows that the interviews added after 7:30 would be heavier in the East and Midwest than in the South.
The telephone interviews done among early and absentee voters explain why so few late interviews were done in the West. Two reasons: First, the telephone interviews were done before Election Day, so all of these interviews were included in the very first tabulations. Second, nearly two thirds of the telephone interviews (65% by my count) were done in Western States (Oregon, California, Washington, Colorado and Arizona). The East region included not a single telephone interview. Thus, two thirds of the votes cast in the West were already included in the data by 7:33, a time when the final reports of the day were likely still out for much of the East.
4) Why all the continuing confusion about all of this more than two months after the election?
Let me quote from the a comment by “NashuaEditor” “Luke” posted here last night (referencing information links from his the new blog NashuaAdvocate):
CBS has a published “final” draft of the Mitofsky Methods Statement on its website which says 11,903 non-telephone and 500 telephone interviews were conducted on Election Day, which gives us a sample size (I think we can now agree) of 13,903 (11,903 + [500*4
2]). This is actually 243 responses higher — not 59 — than the reported 13,660-voter sample size for the National Exit Poll [The 13,660 sample size is also reported elsewhere on the CBS site]Why would CBS, an NEP member, have different data than its data-supplier, Mitofsky/Edison Media, more than two months after the general election? And why would that incorrect data be in the form of a *Mitofsky*-produced Methods Statement?…
I also can’t for the life of me figure out how the Washington Post was reporting 13,047 total responses on November 4th, 2004 — especially when this figure was given to the public by The Post pursuant to an “official correction”(!) Usually “official corrections” in The Washington Post can be trusted, right?
These are reasonable questions, and I could guess, but I would rather let Edison/Mitofsky, CBS and the Washington Post speak for themselves. Rather than speculate further, I will email representatives of each of the organizations for comment (including CNN, which also continues to show 13,660 unweighted interviews on its website), and I’ll post their reactions if any here.
For now, I’ll conclude with this thought: The issue quadruple counting of absentee/early telephone interviews in the unweighted data appears to have thoroughly flummoxed just about everyone involved, including yours truly. Most of what I see here is evidence of a lot of confusion about the mechanics of a very complex set of surveys and tabulations. It would certainly help if the networks would be more open about correcting and clarifying the apparent contradictions in their public documents. But evidence of a hoax? That’s quite a stretch.
Mark – thanks for this – it seems to clear up a lot of questions.
One quick comment – the quote that you attributed to me in point 4 is actually nashua’s (and i was going to let it slide earlier, but seeing that you dragged the quote up to one of your posts, Nash presumably meant to say (500*4), rather than (500*2))
Mark – just some other points to add – tho they are necessarily speculative. Your comment about the poll closing times in the East are well taken, although it still leaves some questions (to be answered hopefully by someone!). Only 2 states, NY and RI, closed after 8pm, therefore we *might* be able to assume that the 7.33pm report was actually designed to incorporate all the other East states. We know that interviewers were to report on three occasions during the day, and it appears that there were three sets of reports released. therefore we can *probably* assume that the 7.33pm report was designed to include the third set of reports in the East (generally, the polls closed at 8, interviewers were told to call at 7pm with their *final* report). its true that there may have been some logistical challenges in getting all this accomplished, but its easy to envisage that there was a plan to include the data from all of those states which closed at 8pm into the 7.30 report – similarly, its easy to imagine that the *purpose* of releasing a set of data at 7.30pm was exactly because it *could* include that information – i.e. otherwise they may as well have waited another 30 mins or whatever (alternatively, they may have been trying to fit within a pre-determined media schedule, although they seemed determined not to make ‘early’ calls)
You also make the seemingly reasonable argument that there werent any phone interviews in the East, and that is why the overnight increases in the East seem disproportionately large.
I had also considered this, but my preliminary numbers seem somewhat ambiguous. It appears that the number of phone interviews is as follows: W=282, MW=39, S=177, E=0
which seems to suggest that election day face2face interviews are as follows:
4pm / 733pm / 3-Nov / o/nite increase
East 1746 2077 2888 39%
MW 1913 2648 3520 33%
South 2079 3235 3748 16%
West 619 1075 1512 41%
Nat 6357 9035 11668 29%
(altho there appears to be an inconsistency somewhere in those numbers which i havent been able to resolve at this late hour – lets have another look tomorrow)
i totally agree that this doesnt necessarily point to fraud – but at a minimum there still appears to be some unanswered questions.
finally – you point to the fact that there is relative consistency across the 3 sets of data (4pm, 7.30, nov 3, and the 2000 results cf: http://www.mysterypollster.com/photos/uncategorized/weighted.jpg) in the regional spread, as evidence (of sorts) that everything is above board. my prima facie assumption is that there ought to be lighter n-weighting in the West in the earlier parts of the day, given the time zones – and therefore, consistent distributions throughout the day are more likely to point to something being amiss, rather than evidence of neutrality – otherwise, it seems that we are forced to presume that there is a bias in the Western interviews toward early interviews.
here is the spread (excl phone)
4pm 733pm 3-Nov
East 27% 23% 25%
MW 30% 29% 30%
South 33% 36% 32%
West 10% 12% 13%
100% 100% 100%
its getting kinda late – so ill just present these without comment – other than its not obvious that they fit the presumed pattern.
again – its not obvious that theres any fraud, but there still appears to be some unanswered questions.
its getting late, and im losing my lucidity (lukidity?).
(i fear ill have to apologise/clarify tomorrow for not making any sense – i need coffee or sleep)
EMR could help all this speculation quite easily. it sucks that we all waste so much time speculating…
MP, I believe you are making a fundamental methodological mistake, which is to assume that the NEP analysis is credible, and that it is for *us* to prove that it is a hoax. There data is innocent until proven guilty, even though it is for them to know and us to find out.
If a scientist has his raw data and analysis procedure questioned, he has to cough up his logbooks for scrutiny by his colleagues. He can hide behind “confidentiality” if he likes, but then we get to discard his data until it can be replicated. Irreplaceable data can’t be replicated.
This is not a game. Why is “Votescam”–a model used to generate and replicate election results a priori improbable? Would you believe the statistics of one cancer study, conducted by the Tobacco companies? Would you want multiple studies, or scrutiny of the data?
The credibility of NEP has been seriously impugned and each day that passes without raw data and code makes it less credible. As far as I am concerned, it is a hoax until we see the raw data. The witness has been impugned and there is no further point in playing a cat-and-mouse game with them in which it is for them to know the answers and us to puzzle over the leaks.
If they want credibility, they can release the data now. If they don’t and we want to know, we can bring the Sherman Anti-Trust act to bear on the media monopoly. Maybe for the cost of a Dept. of Justice proceding on the scale of Microsoft we can sift through their e-mails and learn the truth in a forensic sense.
In any event, no address has been made for these substantive points:
1. If the House and President tabulations differ in the way you say, why is the N for the last line of all the tables in the PDFs (number who say who they voted for) the same in each House file and its paired president file, region-by-region?
If the tabulation program is broken, we can’t believe its output (QA 101: you can’t trust broken programs). Hence my contention that the PDF files are no evidence at all, except in a forensic, QA sense. What was given to the networks is Garbage Out =simpliciter=, even if it bears some semblance to an actual correct tabultation, which we’ve never seen.
2. If the data sets are additive (the House set is a subset of the President set, or close to it), then is that really valid statistically–to have two *correlated* samples to answer two different questions? Even in a random number simulation we should pick a different seed for each run, using a random number table–after we have debugged our program!
Luke,
Sorry about the screw up on Nashua Editor’s comments. My bad. I have a newborn and a toddler at home, a day job (allegedly) at the office, so I sometimes post late at night and such confusion seems to be the price I pay.
About your comments – they are clear. A few thoughts:
1) Though NEP instructed its interviewers to phone in results three separate times, I don’t think we can conclude they intended only three reports. The computer crash reported by the Washington Post apparently prevented at least one interim update. Moreover, the bigger system was designed to deliver complete exit poll data for each state to the networks’ “decision desks” just before the polls close in each state. It seems a safe assumption that designated interviewer call-in times were staggered, both because of differences in time zones and poll closings and to avoid the inefficiency of a crush of calls all at once. Again, as I understand it, one of the biggest logistical challenges is getting all those interviewers to call in report their data completely, accurately and in a timely way.
2) I am not following your point about the distribution of polling place interviews (I probably didn’t read it carefully enough). However, there is only so far we can go with our guessing game. At some point, we just don’t know.
3) The consistency of the regional distribution during the day is evidence that the survey designers wanted it to look that way. That is, they tried to get the national sample to “project” the ultimate national turnout as closely as possible at any time. That was the expectation of the NEP clients, as reflected in the later comments and criticism by the likes of Steve Coll, John Gorman, Mickey Kaus, et. al. Granted, that meant that at about 7:30, the national poll would have been a mix of “complete” samples and partial samples, but that was the best snapshot available. It is also a reason why the people making the network projections pay much more attention to the state samples and estimates than the national exit poll.
I agree – and have always agreed — that a lot more transparency is in order.
MP
This one is for MP:
MP says, “The answer seems simple: Many who turn out on Election Day cast a vote for president but skip the lesser offices. In the 2000 election, according to America Votes, there were 105.4 million votes cast for President and 97.2 million for the U.S. House. The difference was 7.8% of the presidential vote – roughly the same percentage as the difference on the exit polls.”
You know, of course, what HL Mencken said about simple answers. In any event, if the President crosstabs have extra data rows in them above and beyond the crosstabs filtered for the House races, then presumably that is because those extra people at least voted for president and said so.
Don’t you find it a bit suspicious that absolutely *all* of those 8.7% extra records include not a single person who answered the last question–who did you vote for, for President?
Even if you fall back on your “split the form” excuse you have a problem–why bother to include summaries in the Presidential crosstabs for questions that aren’t even tabulated 10% of the time? That’s misleading to say the least!
I think the explanation is even simpler than MP does–programmers are lazy and they write query filters so that you have to be awake when you interpret the results. All the data shows up in every form, whether or not it makes sense for that data set. These PDFs get handed out like candy to news media with no explanation, even though they contain “outer join” data that is clearly irrelevant.
Taking millions of dollars and handing out a mix of meaningful and meaningless data that predict the outcome of POTUS, mentioning 99.5% in the same breath (to give your bilge the air of legitimacy), then having news media call the races based on Garbage Out is a scandal and a blunder.
Also: have we somehow forgotten the bias problem that everyone noticed from day one? If you mix two data sets incorrectly, you get high variance too, by sheer blunder if not design. When you find a cluster of problems in tabulation with the last rows of the table (and the last region–West) *and* unexplained variances (high chi-squared in states with Telephone interviews), is not the simplest explanation an incorrect tabulation of heterogeneous data sets?
Time to get Occam’s Razor out and give Santa Claus a shave.
John asks…
“1. If the House and President tabulations differ in the way you say, why is the N for the last line of all the tables in the PDFs (number who say who they voted for) the same in each House file and its paired president file, region-by-region?”
Because most answer both questions, a fair number skip the Congressional vote question, a very small number skip the presidential question, and an even smaller number skips both.
Let’s take the last national release on 11/3 and use unweighted records (rather than interviews) for simplicity: We know from the NEP methodology statement that there were 13,719 unweighted records (as per Monday’s post). We know that there were 13,660 records on the Presidential pdf, 12,649 rrecords on the US House pdf, 12,605 records that show up consistently in each file for the cross-tab of the two. That means:
* 12,605 records had answers to both questions (hence the crosstab, which requires answers to both questions as executed in the pdf, has a consistent n-size of 12,605 on both tables)
* 1,055 answered the presidential question but skipped the congressional question (13,660 – 12,605)
* 44 answered the congressional question but skipped the Presidential question (12,649 – 12,605)
* 15 skipped both (13,719 – [12,605+1,055+44]).
“2. If the data sets are additive (the House set is a subset of the President set, or close to it), then is that really valid statistically–to have two *correlated* samples to answer two different questions?”
Yes.
And they aren’t two correlated samples, it’s two different tabulations from the same sample.
Thanks, MP. Good. Then, as Columbo says, one more question.
If I subtract the number of persons who answered both President and House, from the number who gave their age, why is it that I get regional totals of -11, 0, 8, 7 for the first set, for a net of 4, but -134, -126, -153, and -173 for the Presidential set, for a net of -586?
And if the explanation is because the “President” data set has exactly those records of persons who answered for House and President (as it must), and in addition those records where President is answered–
Then why is the Pop(5) to Pop(3) tagging difference, in the first data set (all such records are already there and no more are added) — jumps by east = 0, MW= 8, South = 32, and W = 1128?
Clearly, these are the 4-fold records from the Telephone interviews. Yet, we are supposed to believe that including “President but Not House” on top of “President and House” results in essentially no new records E/MW/ST but 314 records in the West?
Looks like horns of a dilemma to me for the incremental data set.
I was just curious, why they dont accumulate all the state exit polls, to get a national exit poll for president that would have extremely small random error?
Summing up the argument on the 2000 records with the Pop(5), Pop(3) and Total:
not West West
Telephone, House and not Pres 206 2
Telephone, Pres or House 216 284
Telephone, Pres and not House 10 282
So records from the telephone subset with both Pres and House are not particularly likely to be added west or east, but records with House but not president are added everywhere except the West, and records with the President but not the House are added in the West only–
Therefore, the data set is hopeless composite, contrived, fraudulant, and scandalous. Thank you, gentlement of the jury.
It gets worse.
It took me a while to see it — the underlying data must have been modified before filtering for House and President, or else there are two data sets not one (but then how are they so much the same?). The assumption we’ve been making,that we are looking at filtered results from the same database, can’t be true–there must be *two* databases with different record sets in them, even though they contain a demonstrable and overlapping subset.
Let’s review the facts as we know them, based soley on analysis of the PDFs and
ignoring the perpetual excuses and special pleadings of our hostile and impugned witnesses at NEP:
1. We have been supposing that the “House” and “President” tabulations are
tabulations of the same data set, the “exit poll results” and that those data
sets are differ because respondents either do or do not answer the last question, how they voted for Prez or for the House. The way tabulation programs work (supposedly) is that they add up rows in a database that are themselves unmodified by the tabulation process.
Either our assumption about a single DB, or the one about non-modification, will turn out to be false, when we test our additivity assumption below (#7).
Continuing our review —
2. The last row of each PDF gives the number who answered *both* questions on which we are filtering, #H+P, and that number always agrees (between the “House” and the corresponding “President” file) across all the three sets, region by region. This is the number of records in both filters, we have been assuming.
3. The difference between Number of Respondents (NR) and #HP is the number who answered House but not President (#H Only), or President but not House (#P Only). “#P Only” is quite big (7.8% we are told–few hundred per region), “#H Only” is rather small (6, 23, etc.).
The consistent explanation we would like to have is that we have one database with two filters, mostly given by the “House” sample, with a few extra records, and a rather larger filtered version, lacking a few records but with quite a few added for the “P Only” people. Tell me it ain’t so, Joe.
4. There appears to be a set of records for which “Pop(3)” is not filled in. This number of records remains constant in all the data sets, and sums to 2000 for the “President” set and 1812 for the “House” set–both divisible by 4. This set has the same regional signature in all files and was apparently there from beginning and unchanged–or it is an invariant property of the “tabulation” process itself.
5. Some of the records are clearly replicated 4 times, as can be demonstrated by making a cross-tabulation of the N-sizes, classified by data set, region, and question asked. By investigating “undercounts” of various questions, we can see multiples of 4 showing up in each set, and in the various deltas or contrasts one might make between sets. This frequency analysis (similar to naive cryptography, natch) lets us “break” the matrix of N-sizes into its most probable component data sets, to prove hypotheses about how it is constructed, etc.
There are 8 records (2 records*4) in the West that appear to have Pop(5) blank as well, and those two interviews (?) appear in both House and President filters. This might be coincidence or it could be the same two.
6. The undercount,etc. patterns–(row differences in our N-size matrix if each row is a question and the columns are data sets, regions, and filter choices) –correlate between the “House” and “President” sets. There are Q*Q or so pairs of rows to subtract, if Q is the number of (non-partial) Questions, so there is a lot of redundancy for this test. N.Sex – N.Age is a good one to look at, e.g. This is our main reason for believing “House” and “President” are based on the same data set.
NOW IT GETS WEIRD
7. In spite of #6, the House sets and President sets cannot be additive–filtered from the same rows, with the mere addition and subtraction of static data rows.
Let’s use H=House, P=President, HP=both
Here’s the proof: focus on the first data set (PDFs) and the western region. There are 284*4 vs 2*4 records with the “Pop(3) missing” signature in the “Pres” vs. “House” data set:
HP or H Only – 2
HP or P Only – 284
This means “P Only minus H Only” is 282*4. “#H Only”
cannot exceed 6 records (using the technique MP showed up above, subtracting NR – #HP, number of answers to both H and P).
The problem is that there can be only 191 “extra records” at most (1747-1556 = 191), if we use our “NR minus ‘HP both’ ” technique again.
This means we have to give up one of our assumptions: (1) that we can model the tabulation process as filtering static rows of data that is added to but never destroyed or modified, or (2) that “House” and “President” share an initial data set.
The problem is that they demonstrably *do* tabulate the same data as far as the questions are concerned. So how can data both change and not change? Well, it can’t, so either we have two distinct sets to begin with, or something is *changing* the data as it gets tabulated (which is another way of saying your tabulation program has a bug, if what you want it to do is tabulate–you can’t tell the computer the difference, of course, since you don’t know the tabulation program’s requirements!).
So how do you get a data set that both is and is not a tabulation of the same thing? Well, you don’t.
So in conclusion–
8. Either the filtering and tabulating program modifies its dataset as it tabulates it, in such a way however as to keep the Pop(3) and Pop(5) aggregate counts the same, while leaving most of the questions’ data untouched, or –
9. there are two separate databases (two sets of books), to which the same data is being added, with different initial conditions as far as the 1812/2000 subset of data is concerned–remember the unexplained biases in the early exit polls?–but not subsequently modified, and with pretty much everything the same except between them except for the “who voted for president and how” sort of fields.
The last phenomenon is the sort of signature one would get if the “presidential choice” fields had been blanked out selectively in some of the “2000” data set, differentially between the West and non-West regions, dynamically updating the row counts, but failing to affect the Pop(3)/Pop(5) signature. That would explain the “two apparent sizes” paradox of additive data that does not add up. It would also explain the bias that dilutes itself into oblivion.
G’nite
For those who like to see the intermediate steps, here is a tabulation of 500 records
in the first data set, i.e. those tagged by Pop(5) and Pop(3) vs. NR signature:
(“Telephone interviews” only, divided by 4):
West Non-West
HP or H Only 2 206
HP or P Only 284 216
Here are the NR-(#HP), which bound “H Only” and “P Only” if the data sets are additive:
(Full data set, not just the “T1812/T2000” data):
West Non-West
H Only, not P 6 23
P Only, not H 191 450
In theory, you should be able to use this
information to construct a cross-table of maximum and minimum, West and Non-West vs.
H only
HP
P only
Unfortunately, you can’t. Go ahead and try. 🙂
MP – congrats on the newborn 🙂
I get the sense from your latest post that you are getting a little tired of this discussion (which is cool) but i’ll respond anyway (your point about the guessing game is also most valid).
My point about the distribution of polling place interviews was in response to your argument that the reason we got a relatively large jump in the East after 7.30pm was that those numbers were distorted becuase the phone interviews in the West were pre-loaded into the first set of numbers. Therefore, i stripped out the phone interviews – the numbers show that the overnight increase was 39% in the East and 41% in the West – which i maintain is quite odd, given the 3 hour time difference.
Along the same lines, you said “nearly two thirds of the telephone interviews were done in Western States… Thus, two thirds of the votes cast in the West were already included in the data by 7:33, a time when the final reports of the day were likely still out for much of the East.” – it appears as though you have got your logic a bit mixed here – its true that 2/3 *of the phone interviews* were in the West, however they only amounted to 16% of the total interviews in the West.
btw – your table titled ‘distribution of the unweighted…’ includes 4* the phone interviews – 3/4 of those need to be stripped out. it seems to me that the ‘core’ data is as follows:
absolutes:
4pm 733pm 3-Nov
East 1746 2077 2888
MW 1952 2687 3559
South 2256 3412 3925
West 901 1357 1794
Nat 6855 9533 12166
percentages:
4pm 733pm 3-Nov
East 25% 22% 24%
MW 28% 28% 29%
South 33% 36% 32%
West 13% 14% 15%
Nat 100% 100% 100%
(altho we still have that pesky difference with the 12,212 EMR claim) (and the differential with WaPo’s numbers)(and cbs’s official EMR announcement)
it appears as though maybe your references to weighted and unweighted data might be somewhat misleading – the ‘13,660’ set is obviously a result of a mistake of sorts – therefore referring to data-sets as weighted or not appears to be dubious nomenclature.
re your point 3) “The consistency of the regional distribution during the day is evidence that the survey designers wanted it to look that way.” – i find this quite tenuous (tho i’m not familiar with the discussions of others that you mention) – altho perhaps i’m missing your point. You seem to be arguing that in order to get regional % consistency throughout the day, that they were happy to early-sample the West, and late-sample the East. The alternative hypothesis that the numbers were ‘forced’ into that framework seems to be equally valid.
On a lighter note, you said “The issue (of)quadruple counting of absentee/early telephone interviews in the unweighted data appears to have thoroughly flummoxed just about everyone involved, including yours truly.” – can i take credit for breaking this one? world exclusive and all of that? i wish that it was a result of some genius insight or clever analysis or some such, rather than simply noticing that there were differences in the top line – the # of interviews conducted 🙂
cheers
Have fun guys. The point is not really all that hard. In going from the “house”
data to the “president” data there should have been a few interviews dropped
(people who answered house but not president) and quite a few added (people who
answered president but not house). But more things changed in the tabulations than
the number of extra interviews would permit.
The “scoop” PDFs, if authentic, prove that the “tabulation”
program mathematically couldn’t be tabulating. At least not correctly. And by the way, the parts that are broken are precisely 2000 records and all the regional
subtotals of this magic part are divisible by 4. The magic part was there from
the get go and got diluted over time by some other stuff.
It’s actually harder to fake a data set than you might think. Just like its hard
to invent a secret code that is unbreakable–a good analyst can look at sample output and guess both the program that made it and some of the input data. Math and Crypto types could break this data set if they wanted, even if NEP stonewalls the good congressman who asked them for data they can’t ever produce and we never get to the subpoenas and the discovery stage.
Since, historically, the data set is out there, perhaps one day it will rank with the Rosetta stone, or at least the Da Vinci code. 🙂